25/04/2016 | Por Noticias TNE
Investigadores alemanes crean sistema de seguridad que analiza la forma de tu cráneo por el sonido que reproduce.
Si creías que los sistemas de reconocimiento facial, de voz o escaneo del iris eran algo sacado de una película de ciencia ficción, ahora los científicos están creando un proceso mucho más difícil de penetrar que será la clave de acceso del futuro.
Se trata de un sistema de seguridad que reconoce la forma del cráneo por el sonido que hace, la cual es una característica única de cada persona, creado por Investigadores alemanes de la Universidad de Stuttgart, la Universidad de Saarland y el Instituto de Informática Max Planck.
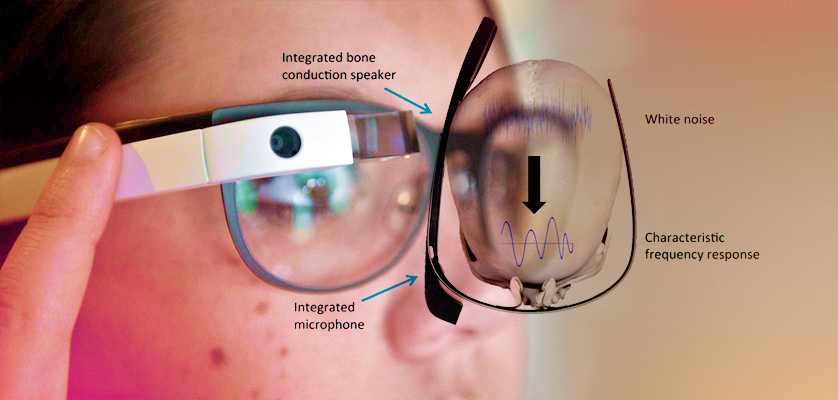
Este sistema biométrico, que aún está en fase de pruebas, es denominado “SkullConduct” y utiliza un casco Google Glass modificado que reproduce un clip de audio de un segundo mediante su bocina y registra el sonido de tu cráneo mientras el eco pasa por éste, ya que cada forma es diferente, por lo que cada sonido registrado también lo es. Las vibraciones y frecuencia dependen de cada persona, como sucede con las huellas de los dedos.
A pesar de ser un prototipo, los investigadores ya han realizado pruebas a pequeños grupos de muestras de un aproximado de 10 personas, el sistema de reconocimiento logró identificar a cada persona con un nivel de éxito del 97%.
“Como la estructura de la cabeza humana incluye diferentes partes como el cráneo, tejidos, cartílago y fluidos, la composición de estas partes y su localización difiere entre cada usuario así que la modificación de las ondas son diferentes de cada persona también” describe el reporte.
Este tipo de tecnología no requiere que tengas que aprender ninguna contraseña, además de que es más difícil para los cibercriminales replicarla, por lo que sería una opción viable para sistemas de alta seguridad, sin embargo, aún tiene cosas que debe mejorar.
Para poder ser totalmente exitoso, el dispositivo tendría que superar el sonido del ambiente para que no se confunda con el del cráneo ni con su frecuencia, además de que actualmente utiliza un audio muy alto y repetitivo como catalizador, lo que podría irritar a los usuarios que lo utilicen. Los investigadores argumentan que éste será reemplazado por un corto clip musical o una melodía agradable.
El equipo de investigadores presentarán el prototipo SkillConduct en mayo durante la Conference for Human-Computer Interaction en San Jose, California.




