
El departamento de investigación de IA de Google, asegura que la nueva tecnología V2A tiene el potencial de revolucionar la creación de contenido hecho con inteligencia artificial, gracias a su capacidad para agregar audio a los videos desarrollados con IA generativa.
La rama de investigación y desarrollo de inteligencia artificial de Google, DeepMind, presentó esta semana una nueva tecnología con la que busca seguir revolucionando la creación de contenido impulsada por IA generativa. Se trata de V2A, un nuevo modelo cuyo nombre hace referencia a la frase “video to audio”, debido a su capacidad para generar música de fondo, canciones y diálogos basándose únicamente en un video y unas simples indicaciones escritas.
A través de una publicación en su blog oficial, DeepMind describe a la tecnología de V2A como una “pieza esencial del rompecabezas” del contenido audiovisual impulsado por IA generativa, ya que a pesar de que existen diversas herramientas para crear videos con base en texto, estas aún no tienen la capacidad de crear audio para darle sonido a la pieza que generan.
“Los modelos de generación de vídeo están avanzando a un ritmo increíble, pero los sistemas actuales sólo pueden generar una salida silenciosa”, escribió la compañía en el comunicado. “Nuestra tecnología V2A se puede fusionar con modelos de generación de video para crear escenas que incluyan música de fondo, efectos de sonido realistas e incluso diálogos que coincidan con los personajes y el contexto del video” agregó.
Además de lo anterior, también puede utilizarse para generar sonidos, música y efectos de audio de grabaciones tradicionales, como material de archivo dañado o películas mudas.
¿Cómo funciona la tecnología V2A de DeepMind?
Los investigadores de DeepMind entrenaron al modelo V2A mediante millones de datos en video, audio y texto, lo que le permitió aprender a relacionar ciertos sonidos específicos con escenas visuales, apegándose a indicaciones textuales proporcionadas por el usuario.
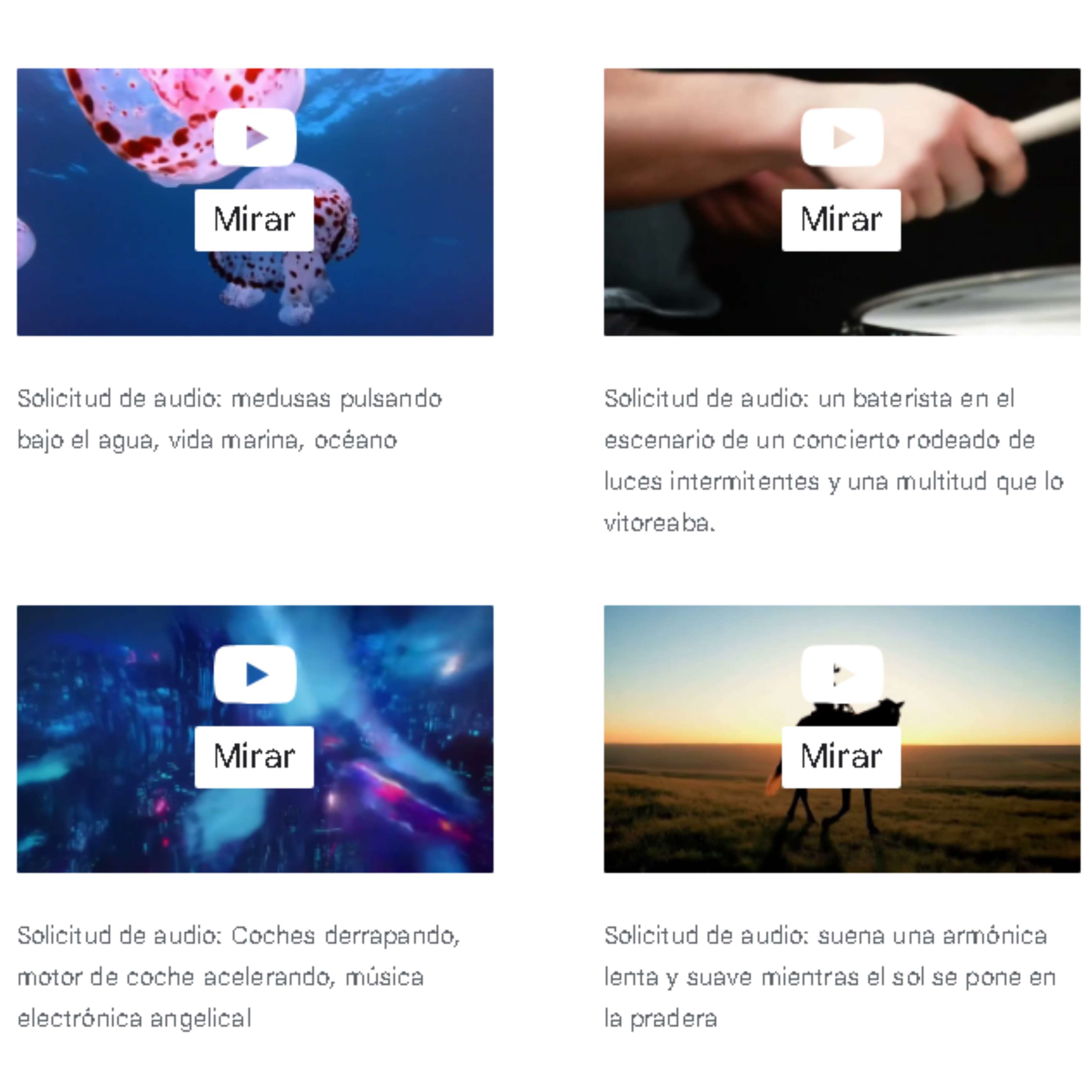
Para lograr generar un audio de mayor calidad y agregar la capacidad de guiar el modelo hacia la generación de sonidos específicos, DeepMind afirma que agregaron más información al proceso de programación, incluyendo documentos con descripciones detalladas de sonidos musicales y transcripciones de diálogos hablados de cientos de películas.
Para generar audios, V2A primero codifica y comprime la entrada de video y posteriormente, comienza a desarrollar un audio a partir del ruido de la imagen, es decir la distribución y el movimiento de los pixeles.
Cabe recalcar que el proceso anterior es guiado tanto por la entrada visual, como por las indicaciones en lenguaje natural proporcionadas en texto a través de un recuadro, para de esta forma, generar un audio realista que se alinee a las indicaciones y se sincronice con lo que sucede en el video. Finalmente, genera audio comprimido, que se decodifica en un formato de audio y se combina con los datos del contenido audiovisual para “darles vida a los cortos generados por IA”.
DeepMind se jacta de que su tecnología se destaca del resto de las soluciones de video a audio existentes porque es capaz de comprender píxeles sin procesar. Además de que el sistema no necesita de alineación y edición manual para empatar los sonidos generados con el vídeo, ya que los sincroniza de manera automática.
Por otro lado, el departamento de investigación y desarrollo de IA de Google presume que V2A puede generar una variedad ilimitada de sonidos, canciones y diálogos alternativos para un mismo video en función a las indicaciones textuales. Esto brinda a los usuarios un mayor control sobre los audios que se crean, además de que les permite experimentar con diferentes descripciones, para obtener distintas salidas de audio, hasta elegir la que más les guste para su video.
¿Qué sigue para V2A?
DeepMind admite que el sistema aun tiene ciertas limitaciones, principalmente porque la calidad del audio que V2A genera está sujeta a la calidad de la entrada de video. Por lo tanto, el contenido borroso o pixeleado, puede provocar que se generen sonidos distorsionados, así como un audio de baja calidad.
Debido a lo anterior, así como para evitar un uso indebido de su nueva tecnología, DeepMind subrayó que no lanzarán V2A públicamente en el corto plazo, sino que en los próximos meses planean seguir trabajando de cerca con creadores de contenido y cineastas para seguir perfeccionando su herramienta.
Finalmente, los investigadores de DeepMind aseguran que someterán a su modelo de IA generativa a “una serie de rigurosas evaluaciones y pruebas de seguridad” antes de lanzarlo al mercado.








