
A medida que la carrera por el desarrollo de la inteligencia artificial más completa continúa, un grupo de investigadores comparó las capacidades de algunos de los principales modelos avanzados de lenguaje con el fin de descubrir cuál es el más preciso en la actualidad.
En los últimos meses, el auge de la inteligencia artificial generativa ha impulsado la llegada de una amplia gama de nuevos modelos avanzados de lenguaje. Con el objetivo de descubrir cuál es el más preciso y cuál el menos confiable en la actualidad, un grupo de investigadores de Arthur AI compararon algunos de los principales modelos de IA como lo son los de Meta, OpenAI, Cohere y Anthropic, a través de una serie de pruebas que demostraron que algunos sistemas “alucinan” significativamente más que otros.
Según Adam Wenchel, cofundador y director ejecutivo de Arthur AI, la plataforma que monitorea la productividad de los modelos de aprendizaje automático en el mundo, señaló que este es el primer experimento que “brinda una mirada exhaustiva a las tasas de alucinaciones de algunos de los sistemas de IA generativa”. Confía en que ayudará a concientizar a las personas sobre las diferencias entre los distintos proveedores actuales de esta tecnología.
¿Cómo descubrieron qué modelo de IA alucina más?
Para poner a prueba la capacidad de los distintos modelos de lenguaje, los investigadores de Arthur AI sometieron a LLaMA 2 de Meta, Command de Cohere, Claude 2 de Anthropic, así como a GPT-3.5 y GPT-4 de OpenAI, a preguntas de tres distintas categorías basadas en matemáticas, presidentes de Estados Unidos y líderes políticos marroquíes.
Los investigadores afirman que las preguntas estaban diseñadas para contener un factor que a menudo provoca que los modelos avanzados de lenguaje cometan errores, refiriéndose al hecho de que exigen múltiples pasos de razonamiento sobre la información.
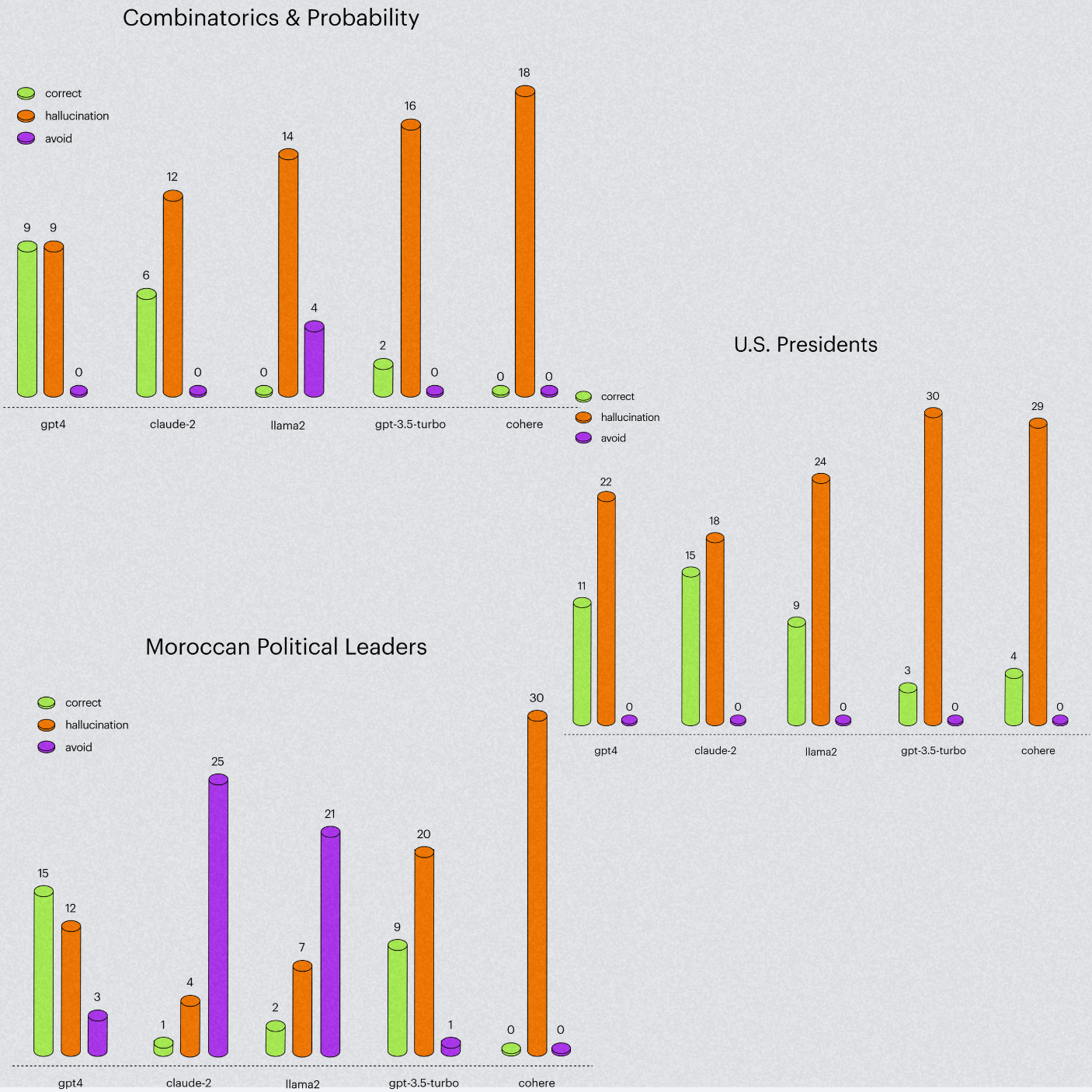
En general, el más reciente modelo de OpenAI, GPT-4, demostró el mejor rendimiento de los cuatro. Además, los investigadores descubrieron que alucina significativamente menos que su versión anterior, GPT-3.5. Por ejemplo, en las preguntas de matemáticas, logró reducir su porcentaje de error entre un 33 y un 50%.
Como contraparte, la investigación reveló que Command de Cohere es el modelo que más “alucinaciones” comete. Es probable que esto se deba a que cuenta con 50 mil millones de parámetros, 20 mil millones menos que LLaMA 2 y más de 120 mil millones menos en comparación con los modelos avanzados de lenguaje de OpenAI.
En la sección de matemáticas, que constaba de 18 problemas razonados, GPT-4 ocupó el primer lugar con un 50% de precisión, seguido por Claude 2 con el 33%, mientras que la inteligencia artificial de Cohere alucinó en cada una de las respuestas de esta categoría.
Por otra parte, en cuanto a las preguntas relacionadas con los presidentes de Estados Unidos, Claude 2 de Anthtropic fue el más preciso, con 15 respuestas correctas y 18 alucinaciones, desplazando a GPT-4 al segundo lugar ya que solo acertó 11 preguntas y presentó información errónea en otras 22. Por su parte LLaMA 2 respondió correctamente en 9 ocasiones y Command únicamente en 4.
Cuando se les preguntó acerca de la política marroquí, GPT-4 volvió a ocupar el primer lugar, mientras que Claude 2 y LLaMA 2 optaron por no responder a la gran mayoría de las preguntas en dicho segmento, siendo conscientes de sus límites al admitir que no cuentan con la información necesaria para responder a eso. Una capacidad que no mostró el chatbot de Cohere, el cual presentó alguna alucinación en las 30 preguntas del tema.
La autoconciencia es un factor clave para evitar las alucinaciones en los chatbots de IA
Adicionalmente, los investigadores realizaron un segundo experimento en el que probaron la capacidad de autoconocimiento de los modelos de IA registrando la cantidad con respuestas en las que los chatbots reconocían que no sabían la respuesta correcta, en lugar de escribir datos erróneos.
Claude 2 demostró ser el más confiable en términos de “autoconciencia”, lo que significa que conoce con precisión lo que sabe y lo que no. Esta capacidad le permite responder solo a las preguntas sobre las cuales tiene los datos de entrenamiento necesarios, reduciendo sus riesgos de alucinaciones.








